max planck institut
informatik
informatik



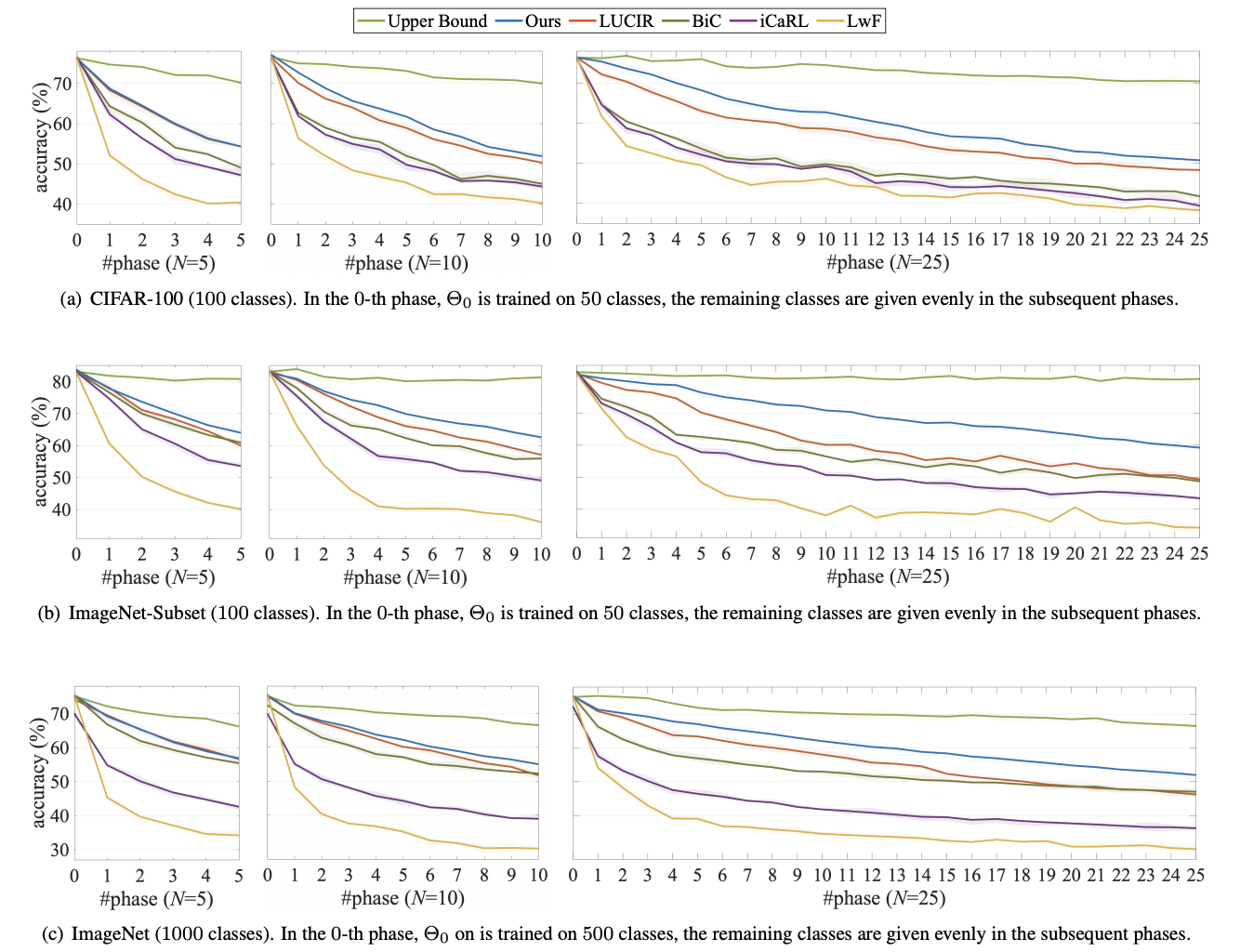
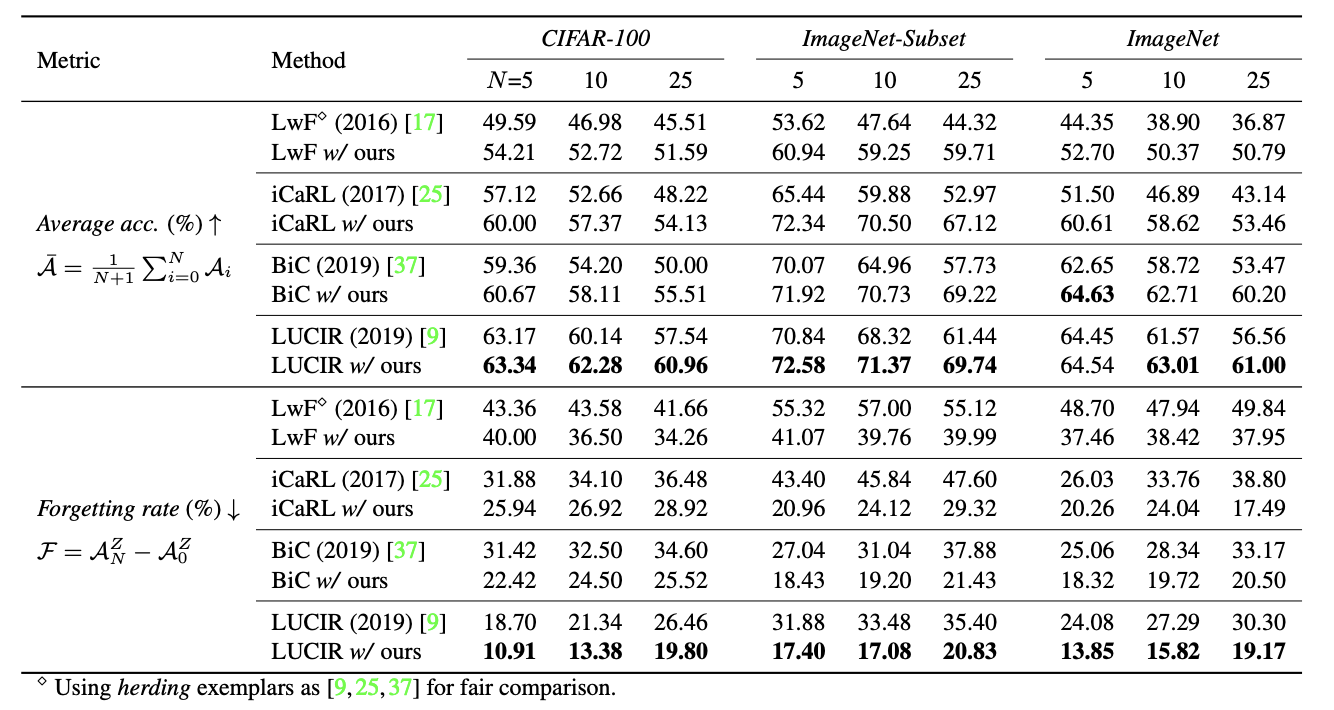
Multi-Class Incremental Learning (MCIL) aims to learn new concepts by incrementally updating a model trained on previous concepts. However, there is an inherent trade-off to effectively learning new concepts without catastrophic forgetting of previous ones. To alleviate this issue, it has been proposed to keep around a few examples of the previous concepts but the effectiveness of this approach heavily depends on the representativeness of these examples. This paper proposes a novel and automatic framework we call mnemonics, where we parameterize exemplars and make them optimizable in an end-to-end manner. We train the framework through bilevel optimizations, i.e., model-level and exemplar-level. We conduct extensive experiments on three MCIL benchmarks, CIFAR-100, ImageNet-Subset and ImageNet, and show that using mnemonics exemplars can surpass the state-of-the-art by a large margin. Interestingly and quite intriguingly, the mnemonics exemplars tend to be on the boundaries between classes.
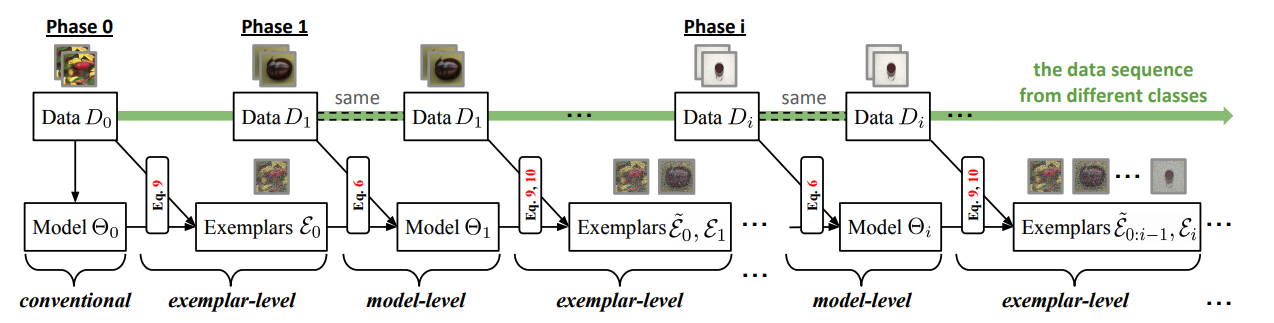
The computing flow of the proposed mnemonics training. It is a global BOP that alternates the learning of mnemonics exemplars (we call exemplar-level optimization) and MCIL models (model-level optimization).
Please cite our paper if it is helpful to your work:
@inproceedings{liu2020mnemonics,
author = {Liu, Yaoyao and Su, Yuting and Liu, An{-}An and Schiele, Bernt and Sun, Qianru},
title = {Mnemonics Training: Multi-Class Incremental Learning without Forgetting},
booktitle = {The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
pages = {12245--12254},
year = {2020}
}
Copyright © 2020-2021 Max Planck Institute for Informatics |
