Class-Incremental Learning (CIL) aims to learn a classification model with the number of classes increasing phase-by-phase. An inherent problem in CIL is the stability-plasticity dilemma between the learning of old and new classes, i.e., high-plasticity models easily forget old classes but high-stability models are weak to learn new classes. We alleviate this issue by proposing a novel network architecture called Adaptive Aggregation Networks (AANets) in which we explicitly build two residual blocks at each residual level (taking ResNet as the baseline architecture): a stable block and a plastic block. We aggregate the output feature maps from these two blocks and then feed the results to the next-level blocks. We meta-learn the aggregation weights in order to dynamically optimize and balance between the two types of blocks, i.e., inherently between stability and plasticity. We conduct extensive experiments on three CIL benchmarks: CIFAR-100, ImageNet-Subset, and ImageNet, and show that many existing CIL methods can be straightforwardly incorporated on the architecture of AANets to boost their performances.
Contributions
A novel and generic network architecture called AANets specially designed for tackling the stability-plasticity dilemma in CIL tasks;
A BOP-based formulation and its corresponding solution for end-to-end training of the two types of parameters in AANets;
Extensive experiments on three benchmarks by plugging AANets in four baseline methods.
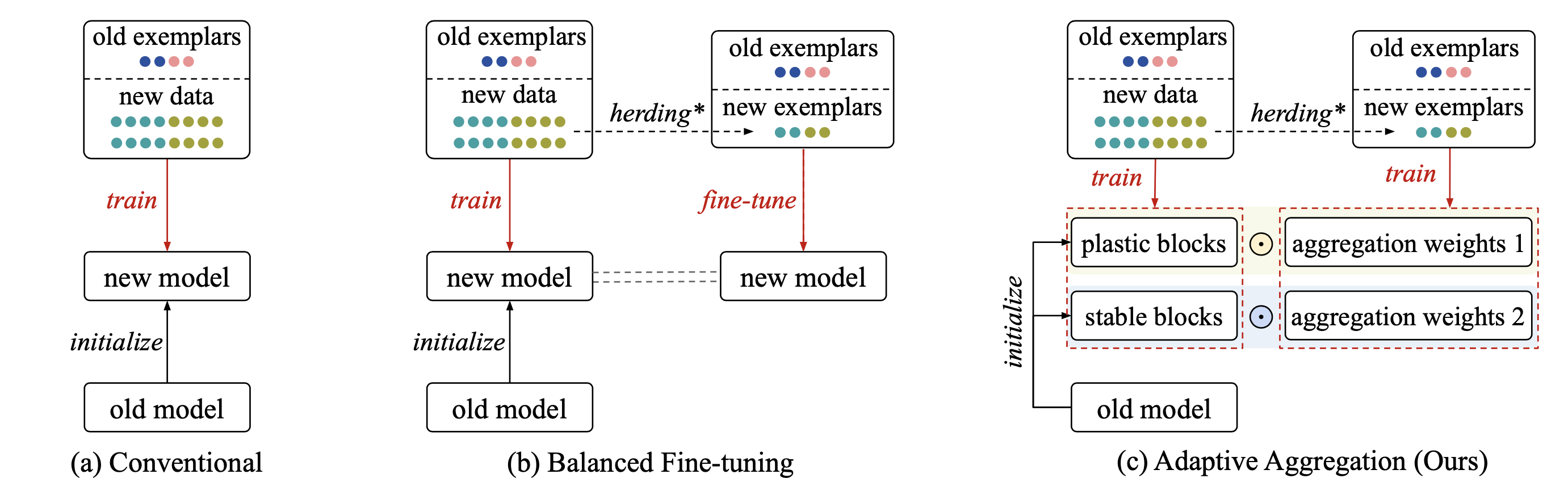
Fig 1.
Conceptual illustrations of different CIL methods. (a) Conventional methods use all available data (which are imbalanced among classes) to train the model. (b) Recent methods follow this convention but add a fine-tuning step on a balanced subset of all classes. (c) The proposed Adaptive Aggregation Networks (AANets) is a new architecture and it applies a different data strategy: using all available data to update the parameters of plastic and stable blocks, and the balanced set of exemplars to meta-learn the aggregation weights for these blocks. Our key lies in that meta-learned weights can balance the usage of the plastic and stable blocks, i.e., balance between plasticity and stability.
Fig 2. An example architecture of AANets with three levels of residual blocks. At each level, we compute the feature maps from a stable block (blue) as well as a plastic block (orange), respectively, aggregate the maps with meta-learned weights, and feed the result maps to the next level. The outputs of the final level are used to train classifiers.
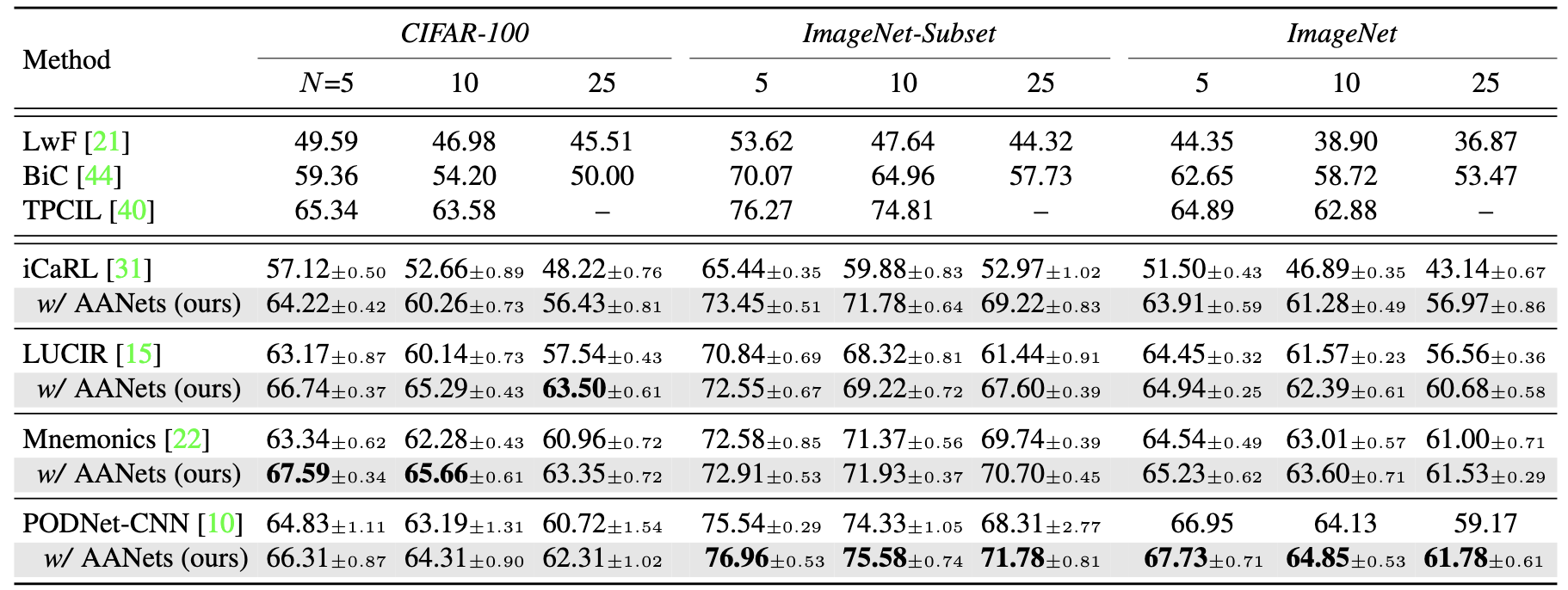
Performance
Table 1. Average incremental accuracies (%) of four state-of-the-art methods w/ and w/o our AANets as a plug-in architecture. In the upper block, we present some comparable results reported in some other related work.
We provide the accuracy for each phase on CIFAR-100, ImageNet-Subset, and ImageNet-Full in different settings (N=5, 10, 25).
You may view the results using the following link:
[Google Sheet Link]
Please note that we re-run some experiments, so some results are slightly different from the paper table.
Download the Dataset (ImageNet-Subset)
The following datasets can only be used for iCaRL and LUCIR w/ AANets.
You need to create the datasets for PODNet w/ AANets following PODNet.
We create the ImageNet-Subset following LUCIR.
You may download the dataset using the following links:
Please note that the ImageNet-Subset is created from ImageNet. ImageNet is only allowed to be downloaded by researchers for non-commercial research and educational purposes. See the terms of ImageNet here.
Citation
Please cite our paper if it is helpful to your work:
@inproceedings{Liu2021AANets,
author = {Liu, Yaoyao and
Schiele, Bernt and
Sun, Qianru},
title = {Adaptive Aggregation Networks for Class-Incremental Learning},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
pages = {2544-2553},
year = {2020}
}
Contact
If you have any questions, please feel free to contact us via email: yyliu@cs.jhu.edu.